28.5.2006
Diese Episode erscheint erstmalig als Audio- und Video-Podcast.
Mit freundlicher Genehmigung vom Software und Support Verlag konnte ich meine JAX-Session vom 10.5.2006 mitschneiden.
Das Ergebnis ist ein Vortrag im Stil von Lawrence Lessig (500 Folien in 70 Minuten), weshalb sich ein audiovisuelles Medium anbot.

Sie können den Vortrag als MP3 und iPod Video herunterladen.
Zum Abspielen des Videos benötigen Sie entweder ein aktuelles QuickTime 7 (kostenloser Download) auf Ihrem Rechner oder einen iPod der 5. Generation.
Buzzword-Bingo für das Jahr 2006:
"Web 2.0" und "Social Software" - was verbirgt sich hinter den aktuellen Schlagwörtern wirklich?
Was sind die heißesten Schlüsseltechnologien, welche Startups sind am erfolgreichsten und was sind ihre Erfolgsgeheimnisse?
Ein Exkurs für Entscheider, Entwickler und Entrepreneure.
Web2.0pedia

25.9.2008
Endlich habe ich mich mal dazu bringen können, meinen webinale -Vortrag abzumixen. Die Aufnahmequalität war leider nur durchwachsen, so dass ich erstmals den Levelator ausprobieren konnte. Duftes Tool!
-Vortrag abzumixen. Die Aufnahmequalität war leider nur durchwachsen, so dass ich erstmals den Levelator ausprobieren konnte. Duftes Tool!
Getting Real ist der "Weg" der 37signals. Das frei erhältliche Buch beschreibt ihre Erfolgsstrategien, Geschäftsphilosophie und Designprinzipien. Die geplante zweite Auflage soll noch stärkeren Business-Fokus bekommen. Sehr spannend …
7.7.2008

Hierzulande viel zu wenig Beachtung gefunden hat in meinen Augen der Stapellauf von Gnip letzte Woche.
Selten kommt ein neuer Service daher, der das Remixen und Mæshen so stark vereinfacht und damit weitergehend demokratisieren wird. Letztes Jahr war es Yahoo! Pipes, 2008 könnte es Gnip werden. War das Motto der Pipes (and Filters) jedoch Mashups für den Rest von uns, werden die meisten Menschen Gnip nie zu Gesicht bekommen. Jedenfalls solange Gnip nur seinen Job erledigt. Denn Gnip will stromaufwärts notwendige moderne Infrastruktur 2.0 bereitstellen.
Was macht Gnip?
Gnip möchte als Nachrichtenbus agieren für Micro-Content aller Art aus allen möglichen Social-Media-Plattformen. Man möchte den Datenfluss zwischen diversen Anwendungen so einfach und portabel wie möglich gestalten und zwar für die Produzentenseite gleichermaßen wie für die anschließenden Konsumenten.
In anderen Worten: Gnip will uns ermächtigen, FriendFeed innerhalb von einem Nachmittag nachzuprogrammieren.
Warum das heutige Aggregationsmodell für Social Media nicht skaliert
Wer heute angebotene Dienste über Web-/REST-APIs oder RSS-/Atom-/JSON-Feeds remixen möchte (grundlegendes zum Thema Mashups), sieht sich folgendem Dilemma ausgesetzt:
- Wir können Datenquellen entweder relativ häufig pollen, um von etwaigen Änderungen schnellstmöglich zu profitieren.
- Oder uns und unserem Gegenüber eine riesige Menge redundanter Anfragen und damit enorme Bandbreite sparen, indem wir größere Latenzzeiten zwischen unseren Anfragen einhalten.
Der Kompromiss besteht zwischen wünschenswerter Aktualität und hoher Informationseffizienz. Ein Twitter-Status, dass ein paar Freunde gerade am Elbstrand Bier + Sonne tanken, ist beispielsweise nicht mehr von besonders hohem Wert, wenn wir die Nachricht zu spät erhalten. Die Gefahr im Gegenzug ist aber, den Anbieter durch eine zu hohe Polling-Frequenz Hast Du wat Neues für mich? … Hey, schon wat Neues? … Jetzt? – jetzt vielleicht wat Neues?
zu überlasten, um dann wahrscheinlich gedrosselt oder womöglich sogar gesperrt zu werden. Beide Seiten verlieren! Daten wollen reisen, Daten wollen frei sein.
Die Crux ist also, die Polling-Frequenz der Änderungsrate auf der Gegenseite anzunähern: einerseits nichts zu verpassen, andererseits aber auch nicht zu drängeln.
Diese Problematik stellt sich bei News-Aggregatoren wie meinem Rivva genauso wie bei Lifestreaming-Diensten wie FriendFeed oder beim ganz normalen Abholen und Lesen der eigenen Feed-Abos. Doch das Problem wächst exponentiell … denn sowohl die Menge remixbarer Quellen als auch die Anzahl vermanschbarer Aktivitätsströme werden über die nächsten Jahre in wohl dramatischer Weise zunehmen.
In FriendFeed lassen sich heute beispielsweise nur 41 der populärsten Dienste einspeisen. Das sind nicht nur viel zu wenig Möglichkeiten, nein, die Sicht ist auch noch viel zu US-zentrisch und schon in einem Jahr wird es Hunderte weiterer relevanter Services geben. Wenn uns das Kreuzprodukt aus x Diensten * y Nutzer * z Updates pro Stunde hier keinen Strich durch die Rechnung machen würde, bräuchte es sowas wie Gnip nicht. Und mindestens einstündliche Updates sind für viele Anwendungen noch das absolute Minimum. Fürs massentaugliche Live-Web versagt dieses Modell ziemlich rasch.
Invertierung der Datenströme – von Pull zu Push
Gnip nun stellt sich als Mittelsmann zwischen die wertschaffenden Content-Plattformen und die davon wertschöpfenden Media-Aggregatoren. Zwei der Launch-Partner sind zum Beispiel Digg und Plaxo: Diggt jetzt jemand eine Story, soll diese Aktivität binnen 60 Sekunden bei Plaxo Pulse erscheinen.
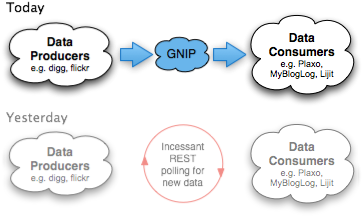
Möglich werden die Nahezu-Echtzeit-Updates, indem man dem Pub/Sub-Modell folgt: Gnip sammelt die Aktivitätsströme an zunächst zentral organisierter Stelle (später solls mal dezentral werden) und verteilt sie sofort an seine Liste von Empfängern.
Die Notifikation kann produzenten- wie konsumentenseitig via Pull oder Push erfolgen. Insbesondere im Push-Mechanismus sehe ich die ermöglichende Schlüsseltechnologie für diverse neue Anwendungen, vor allem aber auch für kleinere Dienste wie Rivva, die sich eine kostspieligere Infrastruktur auch gar nicht leisten könnten.
Bridging zwischen verschiedenen Protokollen und Formaten
Gut gefällt mir dabei die Protokollbrücke: wie man als Quasi-Babelfisch zwischen verschiedenen Ein-/Ausgabe-Formaten und -Protokollen übersetzt: Zur Eingabe dienen XMPP, Atom, RSS und REST. Zur Ausgabe kommt derzeit nur Atom via REST zum Tragen, der Rest soll zu einem späteren Zeitpunkt folgen.
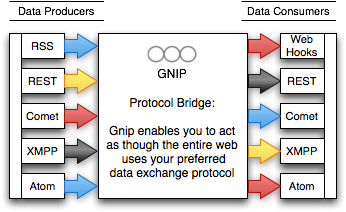
Getreu dem Motto Release Early hat man sich zum Start auf die reine Benachrichtigung zwischen Punkt A und Punkt B konzentriert, der tatsächliche Datenaustausch soll später kommen.
Hohe Datenportabilität durch standardisierte Metadaten
Weitere Karma-Punkte sammelt Gnip für die anbieterübergreifende Standardisierung der verschiedenen Semantiken in den Activity Streams. Hier war man so gut beraten, Chris Messina und seine Arbeit im DiSo-Projekt zu integrieren. Die Gnip API beschreibt, wie unterschiedliche Datenformate nach einer XSLT in einem normalisierten Activity XML konsumiert werden können.
Sehr schön, wie die Gnips auf Standards setzen, wo immer dies möglich war. Kein Mashup-Entwickler dieser Welt wirds vermissen, für jeden anzubindenden Dienst eine kleine Extrawurst programmieren zu müssen.
Summa Summarum
Alles in allem könnte Gnip vielleicht zu so zentraler Wichtigkeit gelangen wie der Push Notification Service fürs iPhone. Die Sterne stehen gut.
Um das Akamai für Web-Services zu werden, müssen sie natürlich noch unter Beweis stellen, dass sie auch hohe Lastspitzen mühelos überstehen. Look Ma, no SQL database zeugt von einem guten Omen.
Showstopper könnte allerdings die rechtliche und insbesondere politische Sachlage werden. APIs sind der neue Klebstoff. Wer sein API in die Hände eines Dritten gibt, tritt damit auch einen Großteil seiner Kontrolle darüber ab. Dass Twitter diesen Schritt machen wird, glaube ich mal nicht.
Update: bin begeistert, Twitter spielt wider Erwarten doch Gnip Gnop
Update #2: Sebastian Keil, Marcel Weiß und ich haben Gnip auf Kanal 14 näher analysiert.
26.10.2007

Ich bin jetzt das erste Mal durch damit: Das ist das wohl beste Fachbuch, das ich seit langer, langer Zeit gelesen habe … und damit für mich Buch des Jahres:
Toby Segaran –
Programming Collective Intelligence
Building Smart Web 2.0 Applications
O'Reilly Media, 2007
So ein dünnes Buch kann natürlich nur eine Einführung geben, doch die ist wirklich großartig!
16.8.2007
Kürzlich stand ich 2x Rede & Antwort zu Rivva:
Letzte Woche hatte ich das Vergnügen, von Mario Sixtus, Nico Lumma + Sebastian Keil zum Klönschnack im Vier-Nasen-tanken-Super-Podcast eingeladen zu werden: MP3 (25:15 Min, 8.7 MB)
Und heute ist noch ein Interview im Förderland erschienen:
27.4.2007

erschienen im OBJEKTspektrum 2/2007
Daten sind langlebiger als ihre Anwendungen. Um ihre Benutzer nicht “einzusperren”, geben Web 2.0-Anbieter den Zugriff auf Nutzerdaten und Anwendungsfunktionalität über Web-Programmierschnittstellen (Web-APIs) frei. Bestehende Inhalte lassen sich dadurch einfach zu neuen, innovativen Mehrwertdiensten integrieren, wodurch eine offene Remix-Kultur entstanden ist, die mittlerweile mehr und mehr Unternehmen erreicht und ihre Datensilos nutzbar macht. Der Artikel (geschrieben 12/2006) beschreibt, wie dieses Mashup-Prinzip funktioniert, warum Unternehmen davon profitieren und welche aktuellen Technologien relevant sind.
Do-it-yourself-Kultur im Web 2.0
Die Demokratisierung der Technologien und Medien hat ganz allgemein, besonders spürbar jedoch im Web, zu einer Renaissance der Do-it-yourself-Bewegung (DIY) geführt. Nutzer
- erzeugen mittlerweile die überwiegenden Webinhalte (User-generated Content),
- führen Fakten zusammen (Citizen Journalism),
- produzieren Text-, Foto-, Audio- und Videostrecken (Participatory Media) oder
- handeln mit selbst gemachten Waren (Social Commerce).
Des einen Erzeugnisse sind des anderen Rohmaterialien. Konsumenten werden zu Produzenten. Was nicht nutzbar ist, wird nutzbar gemacht. Noch nie war das Produzieren, Gestalten und Veröffentlichen so einfach wie im heutigen Netz. Alles wird auseinander genommen, passend personalisiert und miteinander vernetzt. Den Zeitaltern der Massenproduktion und Massenmedien folgt jetzt eines der Maßanfertigung für den einzelnen Konsumenten (Mass Customization). Aufgrund der Internet-Verbreitung finden selbst Nischenprodukte ihre Abnehmer (Long Tail). Auslöser all dessen ist der sich unaufhörlich ausbreitende Individualisierungstrend.
Mashups reihen sich in den Reigen digitaler DIY-Medien als vielleicht eindrucksvollster Ausdruck unserer modernen technischen wie kreativen Möglichkeiten ein. Ein Mashup (deutsch "Vermanschung") verknüpft die Inhalte und Funktionen verschiedener Webangebote zu einem neuartigen Angebot. Amazon trifft Wikipedia trifft Google Maps. Es gibt keine zwei erfolgreichen Web-2.0-Plattformen, die noch nicht miteinander gekreuzt wurden. Tatsächlich rührt der Begriff aus der Musikszene. Als Mashup wird dort das Kunstprodukt bezeichnet, wenn DJs mehrere Musikstücke direkt übereinander legen und beispielsweise die Beatles mit Metallica mixen. Mittlerweile werden allerdings alle möglichen Arten des kreativen Remixes als Mashup bezeichnet. Auch umgestaltete oder neu vertonte Videos auf YouTube oder Fotocollagen von Flickr fallen in diese Kategorie.
Web-APIs ermöglichen Remixbarkeit
Neues entsteht, indem Vorhandenes in noch nicht da gewesener Art und Weise miteinander kombiniert wird. Damit neue Anwendungen nach dem Mashup-Prinzip entstehen können, müssen die beteiligten Komponenten remixbar sein: Dazu gehört, dass Datenströme zugänglich, verwertbar und – insbesondere lizenzrechtlich – verwendbar sind. Im Idealfall würden dazu alle Webseiten eine saubere, offene Programmierschnittstelle (Application Programming Interface (API)) anbieten. Viele Web-2.0-Anbieter tun dies mittlerweile tatsächlich; sie stellen ihre Inhalte Dritten mehr oder weniger frei zum Remix zur Verfügung. Versperren sich Datenquellen dem Mashup dagegen, müssen sie in meist mühevoller Eigenregie erst remixbar gemacht werden, beispielsweise indem die interessierenden Inhalte durch Screenscraping-Techniken aus der HTML-Seite herausgelesen werden. Zunächst einmal will allerdings die Frage beantwortet werden, welchen Vorteil sich ein Anbieter eigentlich davon verspricht, wenn er seine kostbaren Inhalte allgemein zugänglich macht. Als Beispiel diene der Urknall unseres heutigen Mashup-Universums.
Ortsbezogene Dienste als erste Killerapplikation
Die Mutter aller Web-2.0-Mashups ist Google Maps. Als der Suchmaschinenanbieter im Frühjahr 2005 die Verwendung und Manipulation seiner lizenzierten Satellitenkarten über eine einfach nutzbare Programmierschnittstelle ermöglichte, dauerte es nur wenige Tage, bis erste Webseiten auftauchten, die von dem angebotenen Kartenmaterial neuen ungewöhnlichen Nutzen machten. Housingmaps, eine Kombination der Craigslist.org-Immobilienanzeigen auf den Stadtplänen von Google Maps, ist eines der prominentesten Beispiele der ersten Stunde. Chicagocrime tut desgleichen mit der Kriminalitätsdatenbank der Polizei von Chicago und local.alkemis.com lässt uns die Verkehrsüberwachungskameras und Webcams von New York in Echtzeit betrachten.
Dank Google Maps und ebenso Google Earth haben Geoinformationen an zentraler Bedeutung gewonnen. Die Verbindung zwischen dem realen geografischen Ort und seinem digitalen geokodierten Abbild löste von Anfang an besondere Begeisterungsstürme aus und findet deshalb in mittlerweile unzähligen ortsbezogenen Mashups rege Nutzerbeteiligung. Über Plazes z. B. können wir verfolgen, wo sich einzelne Nutzer augenblicklich aufhalten oder welche Personen aus dem eigenen sozialen Netzwerk sich gerade in der Nähe befinden. Bei Qype wird die lokale Suche mit einem Empfehlungsnetzwerk gepaart, um die besten Adressen und Dienstleister der Stadt ausfindig zu machen. Auf Flickr können Nutzer ihren Fotos den Aufnahmeort zuordnen, so dass wir auf der Landkarte genauestens verfolgen können, wo welches Foto geschossen wurde.
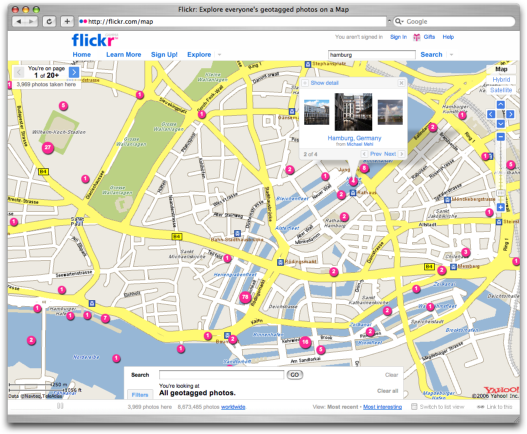
Durch Geo-Tagging hinterlassen Nutzer auf Flickr.com Fotospuren im Netz, die sich weit über den gesamten Planeten ziehen.
Vom Service zur Plattform
Zunächst zurück zur Frage: Was hat Google davon, seine Karten kostenlos unters Volk zu mischen? Nun, ohne die Möglichkeit, den Kartendienst im Handumdrehen in seine eigenen Webseiten einzubinden, wäre das Angebot heute wahrscheinlich “nur” eine als Service bereitgestellte Software von vielen in diesem Segment. Stattdessen ist Google Maps zu einer Plattform für alle Arten von Geoanwendungen geworden. Bei ProgrammableWeb findet sich eine schöne Matrix, die zurzeit 350 APIs und 1.350 Mashups zählt (Stand 12/2006), 40% davon gehen allein auf das Konto von Google Maps, wie z. B. das für Sportler überaus nützliche GMap-Pedometer. Eine riesige Community hat sich inzwischen um die Plattform gebildet. Jedes neue Mashup ist kostenloses Marketing für den Dienst, jeder Nutzer bringt zusätzliche Reichweite und jeder Klick ist weiterer Traffic, der sich in Form von Werbeerlösen in Googles Kasse wiederfindet.
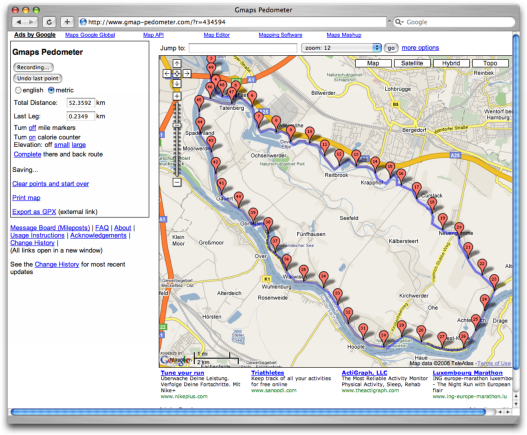
GMap-Pedometer.com verrät Laufsportlern, wo und wie viele Kilometer sie unterwegs waren.
Tatsächlich waren es sogar die Giganten aus der Web-1.0-Ära, Amazon und Ebay, die noch vor Google eine entscheidende Vorreiterrolle für das 2.0-Phänomen spielten. Sie legten einen wichtigen Grundstein, indem sie den Zugang zu ihren internen Datenbeständen öffneten. Zulieferer, Zwischenhändler und selbst Endkunden sollten Informationen schneller und einfacher mit den E-Commerce-Plattformen austauschen können – nicht ohne den offensichtlichen Nebeneffekt natürlich, dadurch ebenfalls größere Reichweite zu gewinnen, mehr Geschäft zu generieren und den Kuchen mit den Kleinen zu teilen.
Daten wollen frei sein
Programmierschnittstellen sind ein hervorragender Weg, um bestehende Anwendungen zu verbessern und zu erweitern. Aus Sicht des Dienstanbieters ist dabei bedeutsam geworden, dass seine Nutzer noch nie so mündig, mächtig und gut informiert waren wie heute. Nutzer möchten ihre Daten heutzutage von Anbieter zu Anbieter mitnehmen können. So genannte geschlossene Gärten, eine Metapher für den berüchtigten Vendor Lock-in, werden im Web 2.0 einfach nicht mehr toleriert. Die Kunden wissen, dass ihre Daten wertvoller und langlebiger sind als die proprietären Anwendungen, die sie tagein, tagaus benutzen. Sie wollen ihre Daten bei einem Anbieterwechsel mit sich nehmen können. Zur Free-Software-Bewegung gesellt sich die korrespondierende Free-Data-Bewegung. Viele Web-Programmierschnittstellen ermöglichen daher sowohl den Export als auch den Import von Massendaten.
Bemerkenswert ist nun, dass die erfolgreichen Dienste trotz zum Teil freizügiger Lizenzmodelle und offener Programmierschnittstellen erhebliche Stammdatenreichtümer anhäufen konnten. Man sollte meinen, dass es zu leicht gemacht wird, Daten zu klauen oder Nutzer abzuwerben. Doch in der Offenheit der Kultur liegt eine der Stärken des Web-2.0-Geistes. Im sozialen Netz geht es um Reputation, Vertrauen und Authentizität. Wer lernt, Güter mit anderen zu teilen, wird belohnt. Und obgleich das Wettrennen um bestimmte Arten wertvoller Stammdaten läuft, teilen alle Teilnehmer bereitwillig via API, was ihnen auf dem Weg in die Hände gefallen ist. So ist Amazon zur ersten Anlaufstelle unter anderem für Bücher und Buchbesprechungen geworden, Del.icio.us für offene Bookmark-Sammlungen, Eventful (EVDB) für öffentliche Veranstaltungen, Flickr für Fotosammlungen, Last.fm für Musikprofile oder YouTube für Videoclips.
Der Umgang mit dem geistigen Eigentum der Nutzer in Web-2.0-Communities und Mashups stellt die althergebrachten Urheberrechtsformen jedoch teils vor größere Herausforderungen. Die kreativ in Community-Angeboten wie MySpace und YouTube ausgelebte Remix-Kultur der vor allem jugendlichen Nutzer gehört zu einem großen Teil zu ihrer Identitätsfindung. Partizipative Medien werden von ihnen wie natürlich neu zusammengestellt, individualisiert und mit Freunden geteilt. Der amerikanische Juraprofessor Lawrence Lessig möchte deshalb mit verschiedenen CC-Lizenzen (Creative Commons) ein dem Internet angemessenes Modell für Fair Use und aktiven Konsum der neuen Medien schaffen. Die Benutzung vieler Web-APIs steht heute entweder unter einer CC-Lizenz oder ist auf andere Art und Weise zur nicht-kommerziellen Verwendung frei.
Small Pieces loosely joined
Mit diesen Worten beschreibt David Weinberger, geistiger Vater des unterdessen wieder modernen Cluetrain Manifestos, die Architektur des Internets. Bisher bestanden unsere Bausteine, um aus Altem Neues zu erschaffen, jedoch lediglich aus kleinteiligen Hyperlinks. Wenn wir zukünftig kleine spezialisierte Dienste lose gekoppelt mit anderen Diensten in oft völlig unvorhergesehenen Formen zu neuen Anwendungen führen können, stellt dies einen wichtigen Schritt in die richtige Richtung dar.
Nachfolgend möchte ich die wichtigsten beteiligten Technologien vorstellen, um Webseiten einerseits remixbar zu machen und andererseits auf ihrer Basis Mashups aufzubauen.
API-Key
Die Nutzung der Web-APIs wird in der Regel über einen benutzerspezifischen Zugangsschlüssel authentifiziert. Auf diese Weise können die Betreiber eines Webdienstes alle Verwendungsszenarien genauestens mitverfolgen und gegebenenfalls optimieren, den Datendurchsatz bei Überlastung drosseln oder Zugangsschlüssel bei Missbrauch bis auf weiteres vollständig sperren.
REST-API
Nahezu alle aktuell entwickelten Programmierschnittstellen setzen auf REST. Das Akronym steht für Representational State Transfer und beschreibt den Architekturstil des World Wide Webs. REST setzt auf pures HTTP und stellt im Vergleich zu SOAP bzw. WS-* (Webservices) eine äußerst pragmatische Lösung dar, die vielleicht jedoch gerade aufgrund ihrer Einfachheit die immerhin größte verteilte Anwendung der Welt hervorgebracht hat: das WWW.
Unter REST stellt alles, d. h. jedes Geschäftsobjekt, eine Ressource dar und jede Ressource bekommt einen Universal Resource Identifier (URI) zugewiesen. Die vier CRUD-Operationen CREATE, READ, UPDATE und DELETE werden durch die entsprechenden HTTP-Verben PUT, GET, POST und DELETE abgebildet. Über das Verb HEAD sind ferner die Metainformationen eines Datensatzes, z. B. Zeitstempel, abrufbar und über OPTIONS ist eine Introspektion möglich, welche Operationen eine identifizierte Ressource überhaupt anbietet. Durch die HTTP-Statuscodes können Fehlerzustände oder Weiterleitungen elegant kommuniziert werden. Gleichzeitig werden saubere, auch von Menschen lesbare URIs verwendet. Blinksale z. B. bietet eine vorbildliche URI-Struktur an:
/clients
/clients/7
/invoices/42/payments
/invoices/42/payments/1
Hinter der URI sind Ressourcen zudem in unterschiedlichen MIME-Typen repräsentierbar. Über den Accept-Header der HTTP-Anfrage verhandeln Client und Server, welche Repräsentation jeweils erwünscht ist. Auf diese Weise können Inhalte über identische URIs unkompliziert in verschiedenen Datentypen ausgetauscht werden, typischerweise als HTML für den Webbrowser sowie in XML für das Web-API und ebenso immer häufiger auch in JSON (Javascript Object Notation).
Javascript, JSON
Auf dem Server kann die REST-Schnittstelle in jeder beliebigen Programmiersprache mittels einfachem HTTP angesprochen werden, auf dem Webclient geschieht dies über Javascript. Daten werden in der Regel in den Formaten XML und/oder JSON exportiert. Letzteres ist eine Beschreibung serialisierter Javascript-Objekte und spart daher das XML-Parsen. Verhalten, d. h. Anwendungsfunktionalität, wird grundsätzlich in Form eines Javascript-APIs zur Verfügung gestellt.
Javascript hat über viele Jahre einen äußerst schlechten Ruf genossen, in den vergangenen zwei Jahren allerdings ein großartiges Comeback gefeiert. Ohne reiche Interaktionsmuster, wie sie nur AJAX (Asynchronous Javascript and XML) und DHTML (Dynamisches HTML) ermöglichen, wird heute kaum eine Webanwendung noch von den Nutzern akzeptiert. Objektorientierte Bibliotheken wie Prototype, JQuery und Script.aculo.us kapseln mittlerweile alle Crossbrowser-Unterschiede sauber weg und nehmen uns das Programmieren von AJAX-Engine und DHTML-Effekten gleich vollständig aus der Hand.
RSS- und Atom-Feeds
Zwei XML-basierte Formate, die sich besonders gut zur so genannten Syndizierung von Micro Content, d. h. dem Verteilen von kleinsten Informationshäppchen eignen, sind Really Simple Syndication (RSS) und Atom. Beide werden serverseitig in Form eines Daten-Feeds publiziert, um clientseitig überwacht zu werden. Über den Feed kann sich jeder Client selbsttätig über Veränderungen auf dem Server auf dem Laufenden halten. Es entsteht der Eindruck eines Server-Push, obwohl das Protokoll ein periodisches Client-Pull ist. Millionen von Webseiten und insbesondere Blogs und Wikis veröffentlichen eine Veränderungshistorie mit beispielsweise den neuesten oder zuletzt geänderten Artikeln in Form dieser Newsfeeds. Allein über XML-Feeds ergibt sich also schon ein riesiger Fundus von remixbaren Inhalten. Jeder Feed stellt dabei einen einzelnen Informationskanal dar, der mehrere Einträge umfassen kann. Durch das Abonnement mehrerer Feeds lassen sich Datenströme aus unterschiedlichen Quellen sehr leicht miteinander aggregieren. Gerade für sich häufig aktualisierende und ereignisgetriebene Ressourcen sind RSS und Atom ideal.
Beide Standards umfassen in etwa den gleichen Leistungsumfang, jedoch unterstützt nur RSS 2.0 auch die Referenz auf binäre Anhänge – Enclosures, die gut zur automatischen Verteilung von Software genutzt werden können, wie es beim Download von MP3-Podcast-Episoden auch der Fall ist. Momentan ist RSS weiter verbreitet, jedoch könnte der nächste Atom-Standard und insbesondere das Atom-API, eine REST-Schnittstelle für alle Arten von Content-Management-Systemen, überaus interessant werden.
SSE
Sobald der Datenaustausch nicht mehr allein durch unidirektionale Feeds abbildbar ist, sondern bidirektionale Kommunikation erfordert, um beispielsweise die Ursprungsressourcen zu aktualisieren oder in anderer Form zu verändern, stoßen semantikarme Formate wie RSS und Atom an ihre Grenzen. Mit Simple Sharing Extensions (SSE) hat Microsoft eine interessante Lösung für seine Live-Produkte vorgestellt, die in diese Bresche schlägt, jedoch noch zu jung ist, um über ihren Markterfolg urteilen zu können.
Ping-Server
Auch Feeds skalieren nicht mehr, sobald Benachrichtigungen in Echtzeit vonnöten sind. In einer Welt, in der alles immer und immer schneller wird, sind Ping-Server das nächste Paradigma: Wann immer irgendwo auf der Welt ein Blog aktualisiert wird, sendet das betreffende Blogsystem eine nur wenige Bytes umfassende Nachricht an Farmen von Ping-Servern. Erhält Technorati ein solches Ping-Signal, wird augenblicklich ein Crawler an die entsprechende URI geschickt, der die neuen Webinhalte absaugt. In weniger als fünf Minuten taucht der neue Blogeintrag im Index der Suchmaschine auf: Live-Suche für das Live-Web. Wer am Puls der Zeit bleiben will, kommt an Technorati kaum vorbei.
Microformats
Mikroformate reichern Daten bestimmten Typs mit zusätzlichen semantischen Informationen an, so dass sie als strukturierte Daten maschinenlesbar werden. Der Ansatz schlägt den pragmatischen Weg ein, jene Mittel einzusetzen, die ohnehin schon vorhanden sind. In diesem Falle werden CSS-Klassen (Cascading Style Sheets) dazu verwendet, Daten im HTML-Markup in fest definierten Formen auszuzeichnen, also z. B. zu markieren, welche Zeichenfolge eine Postleitzahl darstellt und ob eine angegebene Telefonnummer zu einem privaten oder geschäftlichen Anschluss, einem Mobilfunktelefon oder einem Fax-Gerät gehört.
Der Ansatz hat eine Graswurzelbewegung in Gang gesetzt, die sich dem semantischen Web bottom-up annähert. Dazu sind bisher mehrere Dutzend Mikroformate vorhanden, für alle möglichen Verwendungszwecke in verschiedenen Reifegraden. Gänzlich ohne Gremienarbeit hat die um das Microformats-Wiki wachsende Community im persönlichen Einsatz eine Reihe von De-facto-Industriestandards zur semantischen Kennzeichnung von beispielsweise Adressinformationen (hCard), Rezensionen (hReview) oder Terminen (hCalendar) definiert. Über ein Firefox-Plugin kann ein ausgezeichnetes Mikroformat per Knopfdruck exportiert werden, beispielsweise um eine Adresse in den Organizer zu übernehmen.
scrAPIs
Sind Daten semantisch nicht weiter gekennzeichnet, besteht nur die Möglichkeit, sie über althergebrachte Screenscraping-Methoden eigenhändig aus der umgebenden HTML-Seite zu befreien. Dieser Weg führt jedoch dazu, dass ein Großteil der Arbeit in das Schreiben kleiner Parser, XPath-Ausdrücke und regulärer Ausdrücke fließt. Zudem ist diese Strategie äußerst fragil gegenüber Änderungen am Seitenaufbau der betreffenden Inhalte. Als letzte Alternative zum nicht vorhandenen Web-API sind Screenscraping-APIs (scrAPIs) jedoch äußerst brauchbar, wenn unter Umständen auch sehr pflegeänfällig.
Der Dienst Dapper ist in der Lage, selbst für API-lose Webseiten noch ein maßgeschneidertes Interface zur Verfügung zu stellen. Über einen eingebetteten Browser wird der Dienst trainiert, welche Informationen zu extrahieren sind. Die Exportformate reichen dabei von HTML, XML, RSS, JSON und E-Mail-Benachrichtigungen bis hin zu schon vorbereiteten Mashup-Möglichkeiten.
Greasemonkey
Mit der Firefox-Extension Greasemonkey können Webseiten via Javascript im Handumdrehen umgeschrieben werden, noch bevor der Browser den Seiteninhalt darstellt. Der Kolumnist Jon Udell demonstriert in einem Screencast, wie er die Merkliste von Amazon dazu missbraucht, um auf der HTML-Seite des Buchverkäufers im DIY-Prinzip einzublenden, ob und in welchen Bibliotheken die Bücher seiner Liste ausleihbar sind. Webseiten zu remixen, ist zwar schon seit vielen Jahren auch mittels Proxies möglich, war allerdings noch nie so einfach wie mit dem Firefox-Plugin.
Widgets
Mithilfe einer Programmierschnittstelle können Nutzer eigene Ideen umsetzen, an die der API-Anbieter nicht gedacht hat oder für deren Umsetzung keine Kapazitäten vorhanden sind. Um zahlreiche Web-2.0-Plattformen herum, allen voran Flickr, MySpace und YouTube, konnten sich auf diese Art eigenständige Biotope oder gar kleine Ökosysteme bilden, die heute vielen jungen Startups einen Platz bieten. Leidenschaftliche Nutzer waren es, die die ersten Scriptlets entwickelt haben, um ihre Flickr-Bilder oder Del.icio.us-Bookmarks in so genannten Widgets im eigenen Weblog darzustellen. Anbieter haben den viralen Charakter solcher Guerilla-Aktionen erkannt – schließlich ist jedes Widget kostenlose Werbung für ihren Dienst – und bieten daher entweder zahlreiche Widgets von ihrer Seite an oder unterstützen die Community aktiv.
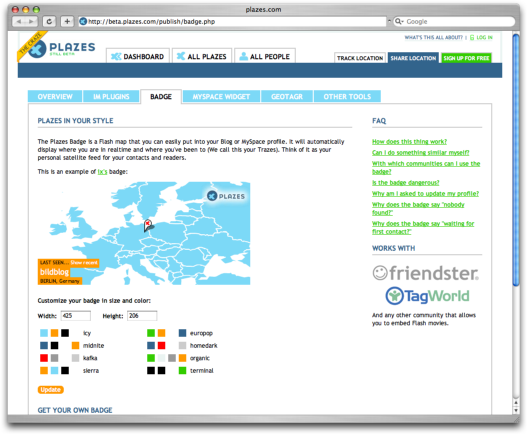
Wie dieses Plazes.com-Badge, sind Widgets für die eigenen Webseiten individualisierbar.
Von Enterprise 2.0 bis Office 2.0
Momentan wird das 2.0-Siegel an wirklich alles geklebt, auch Enterprise 2.0 und Office 2.0 konnten dem Marketingtrend nicht entrinnen. Eine Begeisterung für die Web-2.0-Kultur und den neu aufflammenden Unternehmergeist ist allgegenwärtig spürbar. Verstärkt setzen sich partizipative Medien wie Blogs und Wikis deshalb auch innerhalb von Unternehmen durch. Nicht wenige CEOs füllen täglich den Corporate Blog und nehmen sich das Cluetrain-Credo “Märkte sind Gespräche” zu Herzen. Die PR-Abteilungen überwachen unterdessen die Außenwahrnehmung des Unternehmens über Dienste wie Technorati oder die Google-Blogsuche. Zur Kommunikation werden intern vermehrt Blogs und Wikis, zur Weiterbildung Podcasts und Screencasts, d. h. vertonte Bildschirmmitschnitte, herangezogen. Informationen rauschen in Form von RSS-Feeds in Top-down- wie Bottom-up-Richtung durch die Organisationsstrukturen. Intranetportale sind indes in der Lage, alle für das Unternehmen lebenswichtigen eingehenden Datenströme simultan darzustellen. Schon entdecken erste Unternehmen auch Enterprise Mashups als Dashboard und Information Radiator oder gar als Alternative zur klassischen serviceorientierten Architektur (SOA).
Auch im Office-Sektor tun sich einige interessante Entwicklungen hervor. Sowohl Google Docs (ehemals Writely) und Spreadsheets als auch die Office-Suite von Zoho stellen mittlerweile konkurrenzfähige Online-Alternativen zum Office-Paket von Microsoft dar. JotSpot, wie auch Writely kürzlich von Google vereinnahmt, bietet eine Reihe von Applikations-Wikis an, z. B. für Zeiterfassung, Bug Tracking und Bestellwesen. Socialtext hat Dan Bricklins WikiCalc unter seine Fittiche genommen, ein recht interessanter Ansatz, um Wiki mit Tabellenkalkulation zu kreuzen. Microsoft dringt mit Office Live ebenfalls in den Markt der Online-Kollaborationswerkzeuge, während Google, Gerüchten zufolge, an einem webbasierten Betriebssystem arbeiten soll.
Privatsphäre in Zeiten des Social Webs
Wer sieht, wie viel Information und Privates einige Nutzer im Web über ihr Leben veröffentlichen, mag sich fragen, was Privatsphäre im sozialen Web eigentlich wert ist. Sicher haben wir in Deutschland eines der härtesten Datenschutzgesetze. Technisch gesehen rückt der Spagat, Nutzerprofile und Aufmerksamkeitsströme zu analysieren und zusammenzuführen, jedoch zunehmend von Geheimdienstmitarbeitern in die Hände von Hobby-Stalkern – durch Mashup-Möglichkeiten noch vermehrt und innerhalb von Organisationen insbesondere. Mein Rat lautet daher: Geben Sie im Netz keine Informationen preis, die Sie später vielleicht bereuen könnten oder die Sie auch keiner wildfremden Person auf der Straße anvertrauen würden.
23.3.2007
 Noch ein Interview: Diese Woche mit Thomas Gigold über Rivva, Ruby on Rails und das neue Web.
Noch ein Interview: Diese Woche mit Thomas Gigold über Rivva, Ruby on Rails und das neue Web.
zu lesen bei den Blogpiloten
In other News: Mit Joyent Slingshot sollen Ruby-on-Rails-Apps offline laufen und à la Apollo die Brücke zum Desktop schlagen. Game Changer!
10.2.2007
Großartiger neuer Dienst von Yahoo!: Pipes macht das Remixen von Atom- und RSS-Feeds sowas von kinderleicht, dass Tim O'Reilly schon von einem Meilenstein in der Geschichte des Internets spricht.
Dessen Prinzip lehnt sich an das Pipeline-Konzept aus der Unix-Shell-Programmierung an, wo kleine unabhängige Shell-Kommandos zu mächtigen Pipes-and-Filter-Kommandoketten kombiniert werden können. Die Ausgabe des einen Programms wird dabei direkt in die Eingabe des nächsten Programms gefüttert.
Rip-Mix-Burn
Yahoo! Pipes überträgt diese Idee jetzt auf das Programmierbare Web: Parametrisierbare Module können nach Baukastenprinzip im visuellen Editor (eine Augenweide in sich) zu nicht-trivialen kleinen Mashup-Fabriken verdrahtet werden. Das ist ein großer Schritt in der fortschreitenden Demokratisierung der Medien, da die Möglichkeiten zum Mischen bestehender und Erstellen personalisierter Informationsquellen von einem Tag auf den nächsten in die Hände von Amateuren gefallen sind.
Wie schnell und einfach das wirklich geht, zeige ich mit dem folgenden Comic: Getreu dem Qype-Motto Das Beste der Stadt
siebe ich den Hamburg-Feed nach nur jenen Beiträgen, die die maximale Anzahl von Sternen erhalten haben:
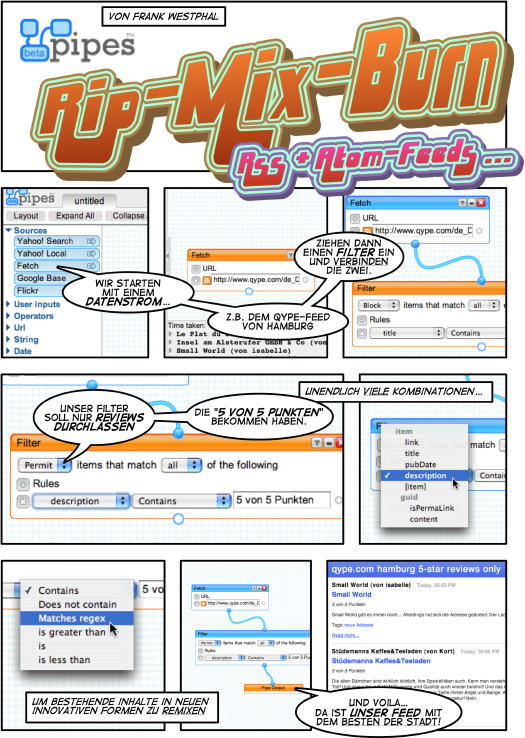
Mashups im Do-It-Yourself
Über das Fetch-Modul können wir beliebige XML-Feeds als Datenquelle anzapfen und so in das wahre Potenzial der Syndizierung von Mikroinhalten tappen. Mithilfe eines URLBuilder hätten wir unsere Query-Parameter noch variieren können, die über User Inputs dann auch durch Nutzereingaben personalisierbar sind. Die wirkliche Mächtigkeit steckt allerdings in den Operators-Modulen: Feeds aggregieren, analysieren, annotieren, filtern, sortieren, transformieren … für alle denkbaren Aufgaben existiert ein leicht konfigurierbares Modul.
Jedes konstruierte Filterstück kann im Debugger-Bereich jederzeit inspiziert werden. Jede Pipe kann wieder als RSS-Feed (auch GeoRSS) publiziert oder als JSON-Baum in die eigene Site eingebettet werden, RDF und Atom sollen als Ausgabeformate folgen, ebenso wie Module zur hübschen Visualisierung (Maps, Badges, …) sowie ein API zum programmatischen Gebrauch der Pipes-Engine.
Pipes können wie jedes andere Modul als fertige Bausteine in anderen komplexeren Pipes verbaut oder einfach hintereinander gekettet werden. Sehr schön auch, dass Yahoo! der View-Source-Kultur des Webs folgt: Erstellte Konstruktionspläne können anderen Nutzern zum Klonen, Auseinandernehmen und Individualisieren zur freien Verfügung gestellt werden. Gerade als angehender RSS-Remixer kann man aus den Pipes-Modellen der erfahrenen Profis extrem viele, coole Kniffe lernen. Mein kleiner bescheidener qype.com hamburg 5-star reviews only
-Remix findet sich hier, der publizierte Feed lautet so.
Technologisch ist auch die grafische Entwicklungsumgebung ein paar Lobesworte wert: umwerfende Umsetzung von Drag'n'Drop und direkter Manipulation im Browser(!) Zum Verdrahten der Pipes-Module wird via Javascript auf einem canvas-Element gezeichnet, als Toolkit kommt die YUI-Bibliothek zum Einsatz.
Fantastische Idee fantastisch umgesetzt … und Google zumindest in puncto Innovation weiterhin voraus!
31.1.2007
Flickr bietet seit letzter Woche offizielle Unterstützung für Machine Tags – ein kleiner Schritt, der in meinen Augen gigantische Auswirkungen auf die Findbarkeit und Remixbarkeit im neuen Web haben wird. Auch als "Triple Tags" bekannt, sind damit Schlagworte gemeint, die (i) einen Namensraum beanspruchen und (ii) ein Schlüssel-/Wert-Paar mitbringen, um mehr Kontext und zusätzliche Informationen zu liefern. Das Tag
flickr:user=frankwestphal
entspricht z. B. einem solchen Triple-Tag-Muster
<namespace>:<predicate>=<value>
Was sind Machine Tags?
Die zunehmende Unterstützung für die Szenarien, wofür die Nutzer den Photo-Sharing-Dienst ohnehin schon nutzen, beweist einmal mehr, wie aufmerksam man bei Flickr seiner Foto-Community zuhört. In Geschick und Gespür für entstehendes Verhalten und innovative Trends ist Flickr wirklich ungeschlagen. So auch in diesem Fall: Lange vor der Einführung des Geo-Tagging (im August letzten Jahres) hatten viele Nutzer ihre Fotos nämlich schon mit den Geokoordinaten ihres Aufnahmeortes getaggt:
geo:lat=53.545974
geo:long=9.970650
Diese dreistelligen Tags werden von Flickr jetzt erkannt, in ihre Komponenten zerlegt und in einer Extra-Datenbank gespeichert. Über das Flickr-API sind Mashup-Entwickler in der Lage, umfangreiche neue Suchen abzusetzen: mit Wildcards anstelle des Namespace, Predicate und/oder Value wohlgemerkt(!)
Sie werden Machine Tags genannt, schreibt Flickr's Dan Catt, weil man davon ausginge, dass diese Form von Tags von automatischen Systemen produziert und später ebenso nur von Maschinen konsumiert würde. Was dem bisherigen Anwendungsszenarien jedoch widerspräche, möchte ich hinzufügen.
Findbarkeit
Nun, was sind die tollen neuen Anwendungsfälle? Zum einen ganz sicher die reichen Möglichkeiten differenzierterer Klassifikation bei gleichzeitig detaillierterer Kontextualisierung (natürlich allerdings nur dort, wo es auch sinnvoll bzw. notwendig ist). Beispiele:
dc:title="Quarters Only, Ocean Beach"
system:filetype=mp3
music:genre=Jazz
sell:price=125.00
sell:currency=EUR
address:street=Reeperbahn
address:postalcode=20359
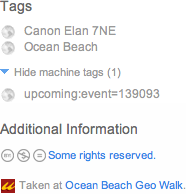
Da maschinelle Tags mehr Informationen tragen als gewöhnliche Tags, wirken sie leicht technisch, nutzerunfreundlich und ruinieren einem zudem noch die schöne Tag-Cloud. :-) Flickr trennt sie daher in einer Extra-Liste von den nutzerdefinierten Tags und macht sie erst nach Mausklick sichtbar (Beispiel).
Die Grenzen zwischen "Form-Style"-Feldern und "Freestyle"-Tags verschwimmen. Machine Tags stellen einen leichtgewichtigen RDF-Ersatz dar, der die Such-, Sortier- und Filtermöglichkeiten komplexer Datenmengen verbessert.
In puncto Darstellung strukturierter, maschinenlesbarer Daten ergibt sich eine kleine Überschneidung mit Mikroformaten. Wo möglich, sollten meines Erachtens immer Microformats vorgezogen werden, da unsere Browser zunehmend in der Lage sind, diese so ausgezeichneten Daten zu interpretieren und mit unseren Desktop-Anwendungen zu verknüpfen.
Remixbarkeit
Ein weiterer Anwendungsfall, der vor allem die Mashup-Möglichkeiten dramatisch multipliziert, ist das direkte Referenzieren anderer Entitäten. Beispiele:
flickr:user=heather
upcoming:event=139093
Ersteres Tag verlinkt aus dem Tag-Set heraus z. B. direkt einen abgelichteten Flickr-Nutzer. Letzteres stellt eine Assoziation zu einer im Upcoming-Dienst referenzierten Veranstaltung her. Flickr setzt in diesem Fall einen Backlink zu dem entsprechenden Event-Objekt. Cool, eh?
Wer Datenbanken kennt, erkennt sofort, dass diese Form von Tags nichts weiter sind als Primärschlüssel in die eigene Anwendung und Fremdschlüssel in andere Anwendungen. Das Prinzip ist trotzdem genial: Das Web-API (idealerweise REST) bildet die Service-Schnittstelle, die Machine Tags die Query-Sprache, das Klassifikationsschema und die Fremdschlüsselbeziehungen ab.
Für mich stellen Machine Tags damit nicht nur die nächste Evolutionsstufe von Folksonomies dar, sondern bringen auch das Web-Prinzip "Small Pieces loosely joined" einen weiteren Schritt voran. Ja, ich hoffe wirklich, dass alle wichtigen Web-Dienste wie in schon so vielen Fällen die Vorlage von Flickr übernehmen und baldmöglichst Gebrauch von Machine Tags machen und Unterstützung für innovative, neue Mashups bieten. Meine Wunschkandidaten?
qype:place=4056
qype:review=438
youtube:video=MKX0RN19zc0
delicious:url=2a2e133a5823afe879fcafc26f7d0612
xing:profile=Frank_Westphal3
wikipedia:en=Folksonomy
15.11.2006

Den lieben langen Tag mit dem Notebook im Café hocken und seinem schönen Leben frönen – kann das Arbeit sein? Die beiden Berliner Autoren Holm Friebe und Sascha Lobo meinen ja und erkennen in diesem Milieu die neue Avantgarde der Arbeitsgesellschaft. Ihr Buch Wir nennen es Arbeit porträtiert den alternativen Lebensentwurf selbstbestimmt und vernetzt arbeitender Kreativer und Wissensarbeiter. Sie nennen sie die digitale Bohème.
Arbeit, Kunst und Leben
Immer mehr Menschen wollen nicht nur so leben, wie sie wollen, sie wollen auch so arbeiten, wie sie leben. Lehrte uns doch schon Konfuzius: Wenn du liebst, was du tust, wirst du nie wieder in deinem Leben arbeiten.
Ermöglicht wird diese Lebenseinstellung, die die Lebenskünstler der früheren Bohème noch am Hungertuch hat nagen lassen, heute durch die Demokratisierung der Medien, die vor allem sozialen Entwicklungen im Internet und den Long Tail.
Hauptziel der neuen Bohèmiens ist nicht das Geldverdienen, sondern der alte Traum vom selbstbestimmten Lebensstil. Auf einen festen Arbeitsvertrag pfeifen sie dankend, stattdessen schließen sie sich in Netzwerken freier Produzenten zusammen und machen ihr Hobby zum Beruf. Denn: Arbeit soll in erster Linie den eigenen Lebensvorstellungen entsprechen.
Das Lebenselexier der Bohème
, wird der Autor Gerd Stein im Buche zitiert, ist die Spontaneität, die als Bedingung jeglicher Selbstverwirklichung begriffen wird und vor allem dann zum Zuge kommt, wenn herrschende Standards außer Kraft gesetzt oder missachtet werden.
Der Individualisierungstrend des 20. Jahrhunderts setzt so seinen Kurs vom Konsum- und Freizeitverhalten in die Arbeitswelt fort.
In einem Satz: Ein zukunftsgewandtes Buch, inspirierend durch die richtige und wichtige Frage, wie zu leben sei.
Bewegtbildmaterial mit den beiden Machern gibts drüben beim elektrischen Reporter. Empfehlen möchte ich auch Paul Grahams Essay How to do what you love.
31.10.2006
Ich glaube, man sollte überhaupt nur solche Bücher lesen, die einen beißen und stechen
, schrieb Franz Kafka einst. Wenn das Buch, das wir lesen, uns nicht mit einem Faustschlag auf den Schädel weckt, wozu lesen wir dann das Buch?

Getting Real – der "Weg" der 37signals – gehört zu diesem Kreis Bücher. 23.000 eBooks haben 37s seit Erscheinen im März im Selbstverlag verkauft. Aber 23.000 Leser sind nicht genug
, erwidern sie auf ihrem Blog. Wir wollen, dass Millionen von Menschen das Buch lesen.
Daher gibts die Essay-Sammlung nun kostenlos online zu lesen. Richtig gut!
Für mich sowieso eines der besten Bücher des Jahres. Am letzten Wochenende hab ichs zum dritten Mal studiert. Jedes Mal bleibt etwas anderes hängen … An Ideen mangelts den Signals jedenfalls nicht. Woran es fehlt, sind Menschen, die sie anwenden. Und zwar extrem.
Was ist Getting Real?
Getting Real beschreibt die Erfolgsstrategien, Geschäftsphilosophie und Designprinzipien der 37signals: Wie entwickelt man in einem kleineren Team schneller bessere Software?
Getting Real eliminiert dazu alles unnötige, was "real" nur repräsentiert (Bilder und Diagramme, Kästchen und Pfeile, Schemen und Wireframes, etc.) und baut stattdessen das "reale" Ding. Lesetipp: There's Nothing Functional about a Functional Spec.
Weniger ist mehr weniger
Getting Real ist weniger. Weniger Gepäck, weniger Software, weniger Features, weniger Papierkram, weniger von allem, was nicht essenziell ist. Der Erfolg von Basecamp, Backpack, Writeboard, Campfire und Ruby on Rails ist u. A. darauf zurückzuführen, dass die 37s-Produkte weniger leisten als die Konkurrenz. Gib den Leuten gerade genug, damit sie ihre Probleme auf ihre eigene Weise lösen können. Und dann gehe ihnen aus dem Weg
, lautet das Motto. Lesetipps: Build Less, Less Software, Less Mass, Human Solutions.
Reduktion Teile, was Dein Produkt sein soll, durch zwei
, YAGNI-Attitüde Verschwende keine Zeit auf Problemen, die Du noch nicht hast
, Fokussierung Jeder neue Feature-Wunsch erhält ein Nein. Wir hören zu, aber wir handeln nicht sofort
, Implikation Was sind die versteckten Kosten eines neuen Features?
und Einfachheit Einschränkungen führen zu Innovation und zwingen Fokus. Anstatt sie zu umgehen, nutze sie zu Deinem Vorteil
sind ihre treibenden Kräfte. Innovation entsteht, indem wir zu tausend Dingen Nein sagen, um sicherzugehen, dass wir nicht in die falsche Richtung laufen oder uns zu viel vornehmen. [...] Nur indem wir Nein sagen, können wir uns auf die Sachen konzentrieren, die wirklich wichtig sind
, wird Steve Jobs zitiert. Lesetipps: Half, Not Half-Assed, It's a Problem When It's a Problem, Start With No, Hidden Costs, Embrace Constraints.
User Experience First
Getting Real beginnt mit dem Interface, den realen Screens, wie sie später benutzt werden. Von der tatsächlichen Benutzererfahrung aus wird rückwärts entwickelt. Dadurch nimmt das Interface den richtigen Weg, bevor die Software den falschen einschlägt. Der Prozess läuft iterativ: Brainstorming von Ideen, Ideen auf Papier skizzieren, HTML-Screens entwerfen, programmieren. Software wird möglichst schnell gelauncht, an neue Gegebenheiten angepasst und fortlaufend verbessert. Lesetipps: Interface First, From Idea to Implementation, Race to Running Software, Test in the Wild, The Blank Slate, Unity, Feel The Pain.
Obwohl die Verbindung nicht explizit gemacht wird, Getting Real ist eine intelligente Übersetzung der Ideen der agilen Entwicklung aufs Business im Web. Derek Sivers sagts allerdings noch am besten: Ideen sind nichts wert, es sei denn sie werden umgesetzt. [...] Es ist ihre Umsetzung, die Millionen wert ist.
Lesetipps: Optimize for Happiness, Seek and Celebrate Small Victories, "Done!".
Getting Real für die Ohren
Im Netz finden sich ein Dutzend Podcast-Interviews mit Jason Fried. Anspieltipps: Edgework, Business Jive, MarketingMonger, Web 2.0 Show, Duct Tape Marketing, Inside the Net, Om and Niall PodSessions, The Prepared Mind, Venture Voice, IT Conversations, Reboot 7.0, IT Conversations.
BTW, hier noch mal der Link zum Buch … Happy Halloween!
15.6.2006
 In ihrer aktuellen Ausgabe 7 nimmt sich die iX dem Thema Mashup mit Web 2.0 an, welches Ramon Wartala (mit Jan Krutisch Gründer der deutschen Ruby on Rails Usergroup) mit gleich zwei Artikeln ausfüllt.
In ihrer aktuellen Ausgabe 7 nimmt sich die iX dem Thema Mashup mit Web 2.0 an, welches Ramon Wartala (mit Jan Krutisch Gründer der deutschen Ruby on Rails Usergroup) mit gleich zwei Artikeln ausfüllt.
Im Rahmen seines Leitartikels haben Ramon und ich uns über QYPE, Web 2.0, Google Maps und Mashups unterhalten: nachzulesen auf Seite 56.
Besonders stolz bin ich ja auf unser Foto mit dem Google Maps Marker, den ich eine Stunde vor dem Interview noch schnell gebastelt habe: unsere Geokoordinate: 53.545974, 9.970650
26.4.2006
 Gestern haben wir nach drei Wochen private Beta die Pforten zu QYPE [kwaip] geöffnet.
Gestern haben wir nach drei Wochen private Beta die Pforten zu QYPE [kwaip] geöffnet.
Entwickelt in einem kleinen XP-Team mit Ruby on Rails.

Was ist QYPE?
QYPE ist eine Empfehlungsplattform für die ersten Adressen Deiner Stadt.
Eine lokale Suche für das Naheliegende im Leben.
Ein soziales Netzwerk von Menschen, die gleich ticken und taggen.
Das Prinzip ist einfach: Tagge auf QYPE, was Dir gefällt, und QYPE sagt Dir, was Dir noch gefallen könnte.
Mehr auf unserem Blog, im ZEIT-Artikel "Näher ran, bitte!" oder eben auf QYPE selbst.
Update 27.4.: SPIEGEL ONLINE bringt QYPE-Story mit Fotos: Gründerzeit im Web-Business: Das soziale Netz
1.5.2005
Begeistert von del.icio.us, Flickr und Technorati Tags habe ich alle meine Webseiten verschlagwortet und das Ergebnis als gewichtete Liste dargestellt:
Klickt man nun auf eines dieser Schlagworte, werden alle zutreffenden Inhalte auf einer Gesamtseite verkettet dargestellt.
Je größer der Schriftgrad, desto mehr Fundsachen zum Thema.
Ein nettes Abfallprodukt der Verschlagwortung ist die "Verwandte Seiten" Spalte, die sich auf allen Einzelseiten wiederfindet:
Hier tauchen alle weiteren Dokumente auf, die ebenfalls eines der Schlagworte des gerade angezeigten Beitrags tragen.
Als Tooltipp angezeigt wird, zu welchem Thema dort weitere Informationen angeboten werden:

17.3.2008
Im Januar/Februar haben Tammo und ich zwei Ruby-on-Rails-Vorträge in der lokalen ACM/GI-Gruppe gehalten. Unser Ziel war es, die Leichtigkeit vorzustellen, mit der wir dank Rails ab Stunde 1 wirklich Geschäftswert schaffen können. Dazu haben wir nach einer kurzen Vorstellung der Prinzipien von Ruby und Rails in einer guten Stunde live eine kleine, aber substanzielle Web-2.0-App entwickelt: mit Kommentaren, Atom-Feed, REST-API, Tags, Google Map, Widget und allem, was dazugehört.
Sie können den Screencast als iPod/iPhone-Video (H.264-Codec) herunterladen und mit beispielsweise iTunes oder QuickTime ansehen. Aufgrund des hohen Demo-Anteils erscheint diese Episode nicht als Audio-Podcast.
Verwendete Plugins
Buchempfehlungen

6.1.2008
Wegen des großen Interesses wiederholen wir den Vortrag am 28.2.
Vor ziemlich genau 7 Jahren haben Tammo + ich in der lokalen ACM/GI-Gruppe unseren allerersten XP-Vortrag gehalten, der irgendwie zu einer kleinen Legende wurde. Am 31. sind wir erneut zu Gast beim HBT und wollen noch mal versuchen, an unseren damaligen Erfolg anzuknüpfen – mit dem aktuellen Thema: Ruby on Rails 2.0
Wir denken, es könnte wieder richtig gut werden … An/kündig/meld/ung
11.3.2007
Am 3. habe ich still und heimlich Rivva gelauncht: einen Meme Tracker, der die deutschsprachige Bloglandschaft nach den aktuellen Top-Themen und Diskussionen – kurz: dem Zeitgeist – durchforstet. Mehr zu den Hintergründen auf dem Rivva-Blog …
27.6.2006
Zwei Events in diesem Herbst unter dem Motto Architecture of Participation:

Endlich ... das erste deutsche Barcamp:
Berlin (30.9.-1.10.2006)

Ebenfalls vormerken: XPdays
Hamburg (24.11.2006)